ComparIA : améliorer les IA conversationnelles sur les usages francophones et former les citoyens
Conçu pour renforcer la diversité linguistique et culturelle dans le développement de l’intelligence artificielle (IA), ComparIA permet à chacun de tester et de comparer des modèles de conversation en français. En recueillant les préférences et usages des internautes, le dispositif contribue à constituer un bien commun de données ouvert, essentiel pour améliorer les performances des IA francophones et sensibiliser le public à leurs biais, à leur pluralisme et à leur impact environnemental.
Le défi des intelligences artificielles francophones
Les intelligences artificielles (IA) capables de dialoguer avec nous comme les agents conversationnels (ou chatbots) s’appuient sur de grands modèles de langue (LLM). Or, ces modèles sont pour la plupart entraînés à partir de textes et données en anglais. Résultat : leurs réponses peuvent refléter des biais linguistiques et culturels, en accordant une place trop importante à la culture anglophone au détriment d’autres langues et points de vue.
L’expansion très rapide des usages de ces modèles rend d’autant plus critique le risque de réduction de la place des langues et cultures française, francophone et européenne dans la production et circulation des imaginaires, d'idées, d'images ou de récits. Ce phénomène pose un défi majeur pour la diversité culturelle, au cœur de la mission du ministère de la Culture.
Face à ce constat, ce dernier agit pour que la révolution de l’intelligence artificielle ne se fasse pas au détriment de la langue française et de la diversité des cultures. Cette action s’inscrit dans la continuité de la politique de défense et de promotion du français dans le numérique, portée notamment par la Délégation générale à la langue française et aux langues de France (DGLFLF).
Elle rejoint également les orientations européennes en faveur d’un numérique souverain et plurilingue, et prolonge les travaux conduits dans le cadre d’initiatives comme ALT-EDIC, consortium européen pour une infrastructure numérique soutenant le développement des technologies de la langue.
Un autre défi concerne la manière dont on évalue ces modèles. Les tests utilisés et corpus d'évaluation pour mesurer leurs performances sont souvent en anglais, peu adaptés au contexte francophone et ne reflètent pas toujours les attentes des utilisateurs français. L’évaluation humaine des performances des modèles en français est coûteuse, difficile à organiser et reste inaccessible à de nombreux acteurs.
L’amélioration des modèles pour les usages francophones suppose donc la constitution et la diffusion de jeux de données en français, indispensables à l’alignement des modèles mais encore trop rares pour soutenir efficacement la recherche et l’innovation dans l’écosystème académique et industriel.
Qu'est ce qu'un jeu de données ?
Un jeu de données est un ensemble d’informations rassemblées et organisées pour être utilisées par des ordinateurs ou des chercheurs. Dans le cas des intelligences artificielles, il peut s’agir de questions posées par des utilisateurs, de réponses fournies par des IA, ou encore de textes et documents.
Ces données permettent aux modèles d’apprendre, de s’améliorer et d’être évalués. Plus le jeu de données est riche et représentatif, plus l’IA peut donner des réponses adaptées à différents contextes et cultures.
C’est dans cette perspective qu’a été conçu ComparIA, un service public numérique porté par l'Atelier numérique du ministère de la Culture. L’Atelier numérique est l’incubateur du ministère de la Culture. Il propose un espace d’expérimentation au service des agents qui identifient un manque ou un problème de politique culturelle et qui souhaitent s’engager personnellement pour le résoudre.
ComparIA : un service pour comparer et comprendre les IA conversationnelles en français
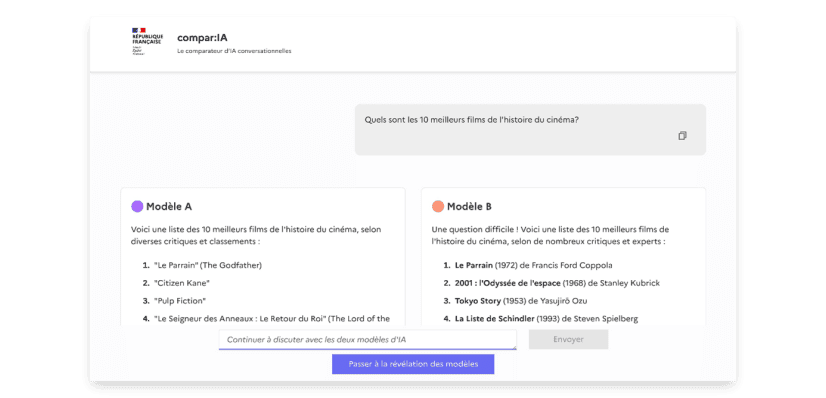
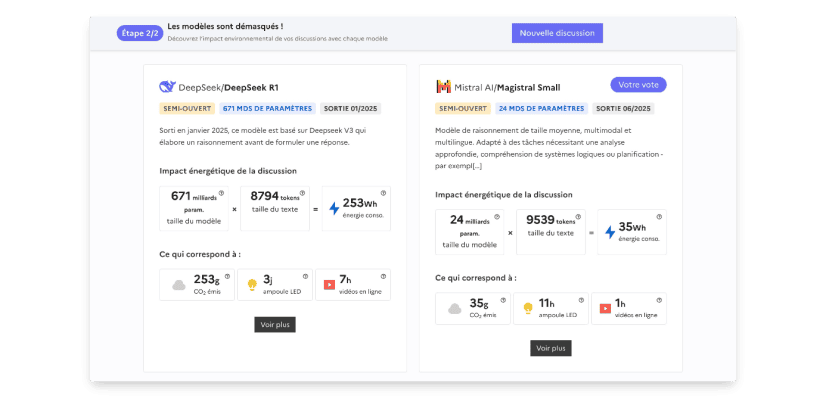
Le site ComparIA permet de tester et comparer les réponses de deux intelligences artificielles (IA) conversationnelles parmi plus de trente modèles, ouverts (open source) comme propriétaires, et de tailles variées. L’utilisateur choisit la réponse qu’il préfère et découvre ensuite l’identité des modèles comparés ainsi que des informations sur leurs caractéristiques et leur impact environnemental.
Les questions posées et les préférences exprimées par les utilisateurs alimentent des jeux de données partagés en open source (sur data.gouv.fr et huggingface.com). Ces données, recueillies dans des situations d’usage réel et non contraint, constituent un bien commun numérique, précieux pour observer comment les IA sont utilisées et pour améliorer les modèles en français. Elles représentent une ressource rare pour l’écosystème de la recherche et de l’innovation.
ComparIA est gratuit et accessible sans création de compte. Il poursuit deux objectifs principaux.
- Former et sensibiliser le public : permettre à tous d’accéder à une diversité de modèles dans une logique de défense du principe de pluralisme (dans la continuité du pluralisme des algorithmes prôné par les Etats généraux de l’information), montrer les biais linguistiques et culturels liés à l’entraînement quasi exclusif des modèles sur des données anglophones, et en démocratisant l’information sur leur impact environnemental encore largement méconnu du grand public.
- Observer les usages et améliorer les performances des IA conversationnelles en français : créer des jeux de données francophones de questions, de préférences et d’usages, particulièrement rares dans le paysage actuel, par l’analyse des usages réels dans un cadre totalement ouvert, et par la constitution progressive d’un classement dynamique des modèles basé sur les préférences d’utilisateurs, une fonctionnalité en cours de développement.
Ouvert au public en octobre 2024, le site rassemble un an plus tard plus de 300 000 visiteurs uniques. En octobre 2025, le jeu de données des questions contient plus de 250 000 entrées et celui des préférences plus de 150 000 (chiffres arrêtés à août 2025). À titre de comparaison, le jeu de données international lmsys-chat-1m, qui sert de référence pour évaluer de nombreux modèles d’intelligence artificielle, ne contient que 1,5 % de conversations en français, soit moins de 20 000. ComparIA multiplie par dix cette ressource et constitue ainsi un apport majeur pour l’écosystème francophone.
Partager la page